
It is always great to host customers at the CSC when they are exploring new Data Center designs or considering new technology they haven’t used before. It’s even better when we can help them on one successful purchase 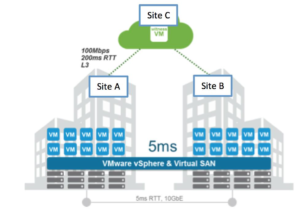 to host them again on a new project. We recently helped a customer that was interested in looking at HCI for a new project. They were interested in replacing a legacy design with Software defined and that included an active-active capability across multiple Data Centers.
to host them again on a new project. We recently helped a customer that was interested in looking at HCI for a new project. They were interested in replacing a legacy design with Software defined and that included an active-active capability across multiple Data Centers.
They had been evaluating several vendors for HCI and we actually helped them test both XC (on ESXi) in a synchronous config and VxRail in a stretched config. The customer had a set of test criteria that meant they wanted to evaluate everything from deployment, through configuration, and failure scenarios plus ease of management and lifecycle updates. The interesting part of this testing was that we hosted the environment built to an agreed design, and then handed it over for their testing – which was all carried out remotely. When they needed to run some functional testing and to simulate node and site failures I jumped on a Skype session and assisted. This sped up drastically the amount of time required by the customer to complete all the testing they required. The timeline was quite tight as the customer needed to draft a comprehensive report on the results to share with their executive board in order to make the purchase decision.
In the end they went with a VxRail vSAN stretched cluster for the first phase of this project. We would later learn from their Partner (and my running buddy @VictorForde) that the second phase of the project was going to involve another VxRail stretch Cluster and Recoverpoint for Virtual machines. Once again they asked could we assist and build out a design that could test Recoverpoint running between VxRail Stretch clusters. This design would allow them to tolerate site failures and also protect against data corruption – giving them the ability to roll back to any point in time copies of their protected VMs. Victor said, “We configured the environment to remote replicate across two Stretch Clusters within a site with PiT rollback to protect across clusters within a site as well as rollback from logical corruption. vSAN does the protection across each side of the cluster so no RP4VM replication traffic between sites.”
Recoverpoint for VMs (RP4VMs) and VxRail with VMware vSAN are better together for several reasons. Firstly VxRail is the simplest starting point for a vSAN cluster. They are easy to size, simple to deploy and make the day to day management a breeze. RP4VMs is really easy to deploy (just drop the latest ova) in a VMware environment. Although RP4VMs is actually storage agnostic – vSAN is an excellent choice for operational simplicity and ease of….well just about everything storage related! RP4VMs uses a vCenter plug-in that tightly integrates management into vSphere and allows customers a simple interface with orchestration and automation capabilities. It only takes 7 clicks to protect a VM! Failing back is fast as well, no need extra step needed to copy the data, just roll through the journal to find the point in time needed. It also rolls from the latest copy back, rather than requires you to roll from the oldest first. 
When the customer was finished with their testing they were confident in deployment, configuration, ease of use and disaster testing. The partner was also happy as they were able to be involved in the entire process from beginning and provide input while also documenting the steps and process involved. In fact the partner saw a future for this project that other customers might also like, they even gave the solution a new name vStretchPoint – not sure if marketing will run with it, but you never know!
Big thanks to the team involved in the testing for this POC they deserve most of the credit too; @sandybryce @victorforde @tebe155 @rw4shaw
Thanks for all your help Mike, Dell Solution centre is a great place to test without the hassle of getting POC kit onsite.
Key point for the setup was to set the default vSAN storage policy to PFTT=1 so that RecoverPoint copy VMs and associate journals can survive a site failure. Also we set up DRS rules to pin the vRPAs to sites with “should” rules with a storage police of PFTT=1 as well so that in the event of a site failure the vRPA, copy VMs, journals etc could all failover between sites. This allowed the data protection to continue once all the VMs had HA recovered to the surviving site.
Not a bother Sandy! I learned a good bit during this POC about RP4VMs and delighted to be able to assist you all. See you in VMWorld Barcelona…